Health insurers receive millions of claims per year. Given that information asymmetries between the principal (insurer) and the agents (health care providers and the insured) can lead to moral hazard, insurance companies face the choice of either paying out insurance claims immediately without any adjustments or reviewing claims that are suspicious. The most common method for undertaking the latter involves manually auditing claims data, which is a time-consuming and expensive process. A cost-minimizing insurance company faces a trade-off between the expected benefits of auditing (above all, the expected value of the adjustments to upcoded or fraudulent claims) and the auditing costs. Machine learning models can greatly cut auditing costs by automatically screening incoming claims and flagging up those that are deemed to be suspicious -- i.e. potentially incorrect -- for subsequent manual auditing.
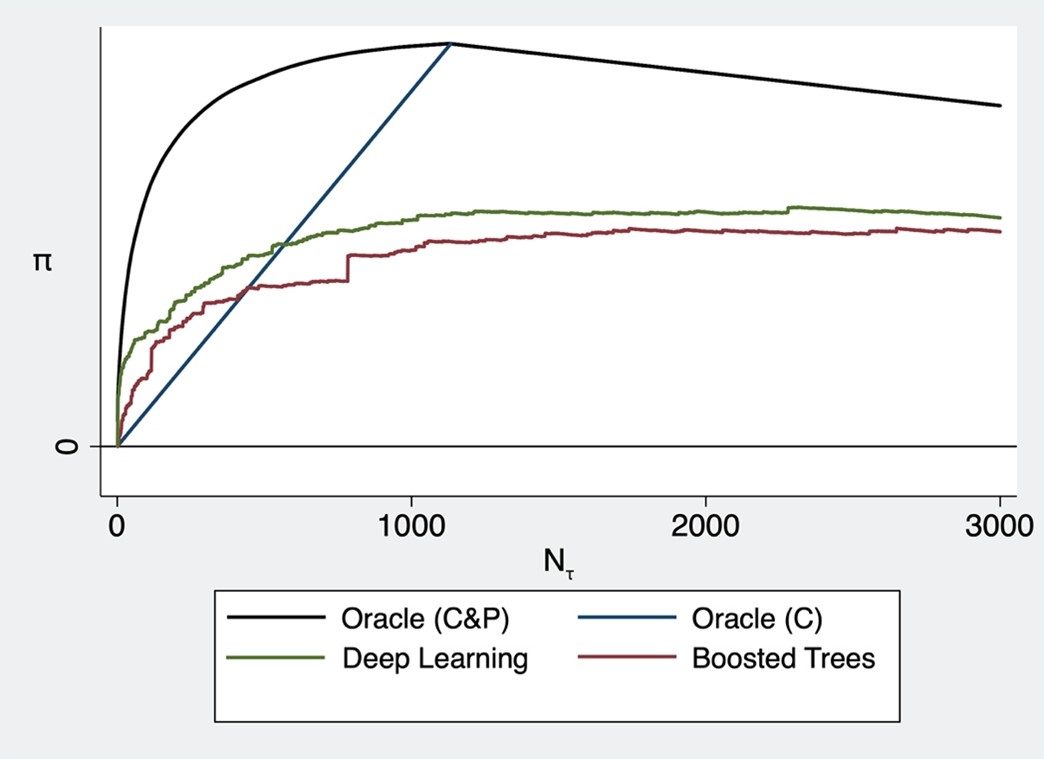
The quality of the automatic screening depends on how well the model can classify unseen claims (i.e. separate fraudulent ones from non-fraudulent ones), and on how well it can prioritize or rank the suspicious claims (i.e. finding claims with high adjustments first). Let a constant number of unseen claims be flagged up by our models and assigned to manual auditing (denoted by N in the figure below). The figure depicts the cost savings if we use our new deep learning (green line) compared to boosted trees (red line), which is a standard machine learning tool. We additionally show in the figure the expected gains from an oracle that randomly draws from the subset of fraudulent claims (blue line). Assignments based on this oracle C benefit only from perfect classification of the fraudulent claims but completely fail with respect to the prioritization task. Both model-based assignments perform better than this oracle at the beginning of the path, which suggests that both models pay attention to the prioritization task. Oracle C&P benefits from both perfect classification and perfect prioritization of the fraudulent claims (depicted as black line). The forgone savings are the differences between oracle C&P and the model-based assignments. Our deep learning model clearly reduces the foregone savings compared to boosted trees for any value of N.
Paper: https://doi.org/10.1016/j.jeconom.2020.05.021
Replication code: https://github.com/farbmacher/claims-management-joe
Altmetric: https://www.altmetric.com/details/91575083